
- Log in to the Azure portal at https://portal.azure.com➢ navigate to the Azure Databricks workspace you created in Exercise 3.14➢ select the Launch Workspace button in the Overview blade ➢ select Compute menu item from the navigation pane ➢ select the cluster you created in Exercise 3.14➢ start the cluster ➢ select the Libraries tab ➢ click the Install New button ➢ select Maven from the Library Source section ➢ and then enter the following into the Coordinates text box. Figure 7.26 illustrates the configuration.
com.microsoft.azure:azure-eventhubs-spark_2.12:2.3.22
FIGURE 7.26 Installing the Event Hubs library on an Azure Databricks cluster
- Click the Install button. Once the Status for the Event Hubs library is Installed, as shown in Figure 7.27, select the + Create item from the navigation menu.
FIGURE 7.27 The installed Event Hubs library on an Azure Databricks cluster
- Select Notebook from the pop‐out menu ➢ enter a name (I used ReadBrainwavesFromEventHub) ➢ select Scala from the Default Language drop‐down list box ➢ select the Cluster where you just installed the Event Hubs library from the Cluster drop‐down list box ➢ click the Create button ➢ and then enter the following code into the notebook cell. The code is in the ReadBrainwavesFromEventHub.scala file in the Chapter07/Ch07Ex06 directory on GitHub.
- Run the code in the cell ➢ using the brainjammer.exe from the Chapter07/Ch07Ex03 directory, send the brain wave readings in the csharpguitar‐brainjammer‐pow‐5.json file located in the Chapter07/Ch07Ex06 directory. The output in the notebook console should resemble Figure 7.28.
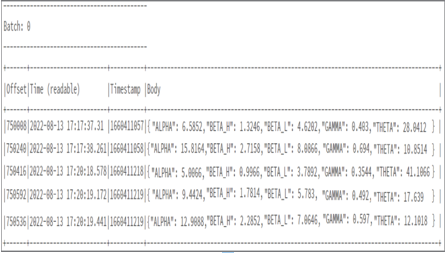
FIGURE 7.28 Streamed Event Hubs messages displayed in the Azure Databricks notebook console
- Click the Stop Execution button, which stops the cluster.
The first action you took in Exercise 7.6 was to install the library required to make a connection to an Event Hubs endpoint. The com.microsoft.azure:azure‐eventhubs‐spark_2.12:2.3.22 library contains methods to create the connection string and configure the Event Hubs listener. You then created a notebook that would eventually contain the code to receive and write the message data sent to your event hub. The first few lines of code, as shown here, import the specific classes from the event hub’s library and then use the provided event hub name and endpoint address to build the connection string.
The connection string is then passed as a parameter to the EventHubsConf class, which is used to make the connection with the Event Hubs namespace and hub. Notice that in addition to the connection string being used with the EventHubsConf class constructor, there is a method named setMaxEventsPerTrigger, which is passed a value of 5. This method sets the maximum number of events to be processed at one time.
val customEventhubParameters = EventHubsConf(connStr).setMaxEventsPerTrigger(5)
An instance of the EventHubsConf class named customEventhubParameters is then passed as a parameter to the options() method as part of the spark.readStream() method. When messages are sent to the event hub from a producer, the messages are then pulled into the incomingStream variable. The message is then formatted into a human‐readable format and stored in message.
val incomingStream = spark.readStream.format(“eventhubs”).
The message is then written to the console using the following syntax:
messages.writeStream.outputMode(“append”).format(“console”).
Chapter 6 introduced the outputMode() method. As you may remember, the different output mode types are Append, Complete, and Update. You might consider doing some additional work using Exercise 7.6 in order to gain a better understanding of how these different output modes affect the rows in the results table. Append mode adds new rows to the table since the last trigger, whereas Complete mode generates the entire table after every trigger, which minimizes the risk of duplication. Update mode adds the rows that were updated since the last event messages were added to the results table. When you set truncate to false, none of the data rendered in the console will be trimmed. This means you will see all the data returned; otherwise, you would see only the first 20 characters. The start() method is what keeps the program listening for event notifications from Event Hubs, which it will continue to do until it is manually stopped or the cluster is shut down. The awaitTermination() method enforces this behavior.
In Exercise 7.6 you did not do the full transformation of the data into median values nor compare them to the ranges per brain wave scenario. This is all completely possible; you just need to write the code to do it. An easy—rather, easier—approach might be to write the messages to an ADLS container that is an input for the Azure Stream Analytics job you already have. The query you have already written could then be used to perform the final stages of the ingestion, transformation, and streaming of the results to Power BI. You could use the following code snippet to store the results into an ADLS container instead of to the console:
val reading = incomingStream.
withColumn(“Body”, $”body”.cast(StringType)).select(“Body”)
reading.writeStream.format(“json”).save(“abfss://@.dfs.core.windows.net/…”)
The format is set to JSON because the Azure Stream Analytics job is expecting that format. However, keep in mind that whenever possible you should use the Parquet format, as it is the most efficient format when consumed by Azure Databricks or PolyBase via Azure Synapse Analytics.
Finally, note that in Exercise 7.6 you used an interactive Apache Spark cluster. This means that you had to manually start the code that read and processed the event message in the notebook. If you wanted to run such a solution in a production scenario, you would need to provision an automated Apache Spark cluster. You might recall the introduction of automated Apache Spark clusters in Chapter 6, in the context of batch jobs. You will need to perform the same action in this context to make sure your streaming solution is running as required. To get the most availability and throughput of your structured streaming solution on the Azure platform, you might consider using Apache Hadoop YARN. Apache Hadoop YARN is available through the Azure HDInsight product offering, which is where you will achieve fault tolerance and seamless integration with other open‐source big data products, features, and tools.


