
Chapter 10, “Troubleshoot Data Storage Processing,” discusses performance and scaling techniques, but this is an appropriate place to introduce these concepts in the context of streaming products. It is important to know how each product scales when an unexpected burst of data is sent to it. Table 7.3 provides some information about how each Azure streaming product scales.
TABLE 7.3 Streaming scalability by product
| Product | Scalability | Dynamic |
| Azure Stream Analytics | Query partition | Yes |
| Azure Event Hubs | Partition | No |
| Azure Databricks | Cluster configuration | No |
| HDInsight with Spark Streaming | Cluster size | No |
| HDInsight 3.6 with Storm | Cluster size | No |
| Azure Functions | Up to 200 parallel instances | Yes |
| Azure WebJobs | Up to 100 parallel instances | Yes |
Scaling basically identifies how additional compute power is allocated to the Azure product when more is required. If the CPUs are maxing out at 100 percent or memory is being consumed, a queue can form, slowing down the ingestion of the stream. Adding another machine to the resource pool could help get the incoming data back under control. Azure Stream Analytics scales based on partitions. If you remember back in Exercise 3.17 when you added the Event Hub input named brainwaves to a Azure Stream Analytics job, there was a property named Partition Key. If the data being streamed is partitioned by a key, then you would gain some scaling efficiencies had you added a value there. Something like electrodeId or frequencyId are examples that could be applicable here. Then, as shown in Figure 7.6, you can scale out to a static or dynamic number of streaming units (SU) that can process data bound to the configured partition. A SU is a combination of CPU and memory allocated for processing streamed data.
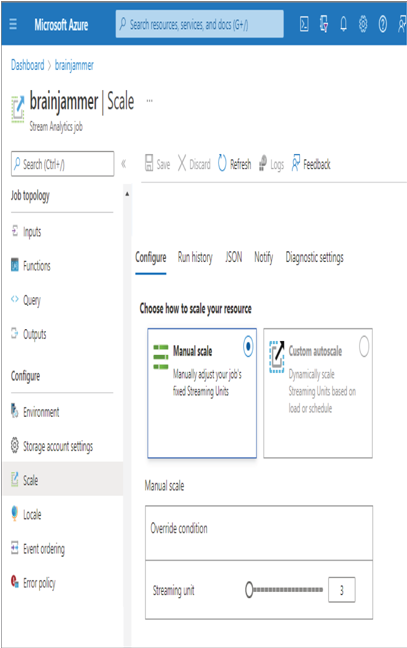
FIGURE 7.6 Azure Stream Analytics scaling
In Exercise 3.14 you provisioned and configured an Azure Databricks cluster. As shown in Figure 3.65, you set the Worker Type option to identify the amount of memory and the number of cores. You also set the Min Workers and Max Workers options to represent the available capacity. The platform will manage the execution of tasks on those workers; however, it will not increase or decrease them any more or less than what they are configured to be. For HDInsight, refer to Figure 3.86, where you learned that a similar configuration option can be used for each HDInsight node type, in that you can configure the node size and number of nodes for each node type running inside your HDInsight cluster. This configuration represents the maximum amount of compute capacity allocated to the cluster for performing data ingestion and transformation. Finally, Azure Functions and Azure WebJobs scale out to a maximum number of instances, where an instance is a dedicated one‐, two‐, or four‐core VM. When a dedicated scale out happens, an exact replica of the VM running your code is configured and added to the compute farm to perform the programed computations. The maximum number of instances is provided in Table 7.3, but you can ask Microsoft to allocate more. Which kind of scaling meets the needs of your data analytics solution? The variety of node sizes is much greater when it comes to HDInsight and Azure Databricks; however, they will only scale out to the maximum number you have configured. While Azure Stream Analytics, Azure Functions, and Azure WebJobs have fewer types of VM SKUs, they will scale out to a very large number of them. Knowing if you need a fixed number of very powerful machines or a flexible number of strong machines can drive your decision‐making process to a specific streaming product.


