
Partitioning has been covered in many different scenarios and contexts. For example, in Exercise 2.2 you provisioned an Azure Cosmos DB and changed the partition key to /pk, and in Exercise 3.16 you provisioned an event hub with two partitions. The purpose and benefits of partitioning should be clear. To summarize: partitioning is the grouping together of similar data in close physical proximity in order to gain more efficient storage and query execution speed. Both efficiency and speed of execution are attained when data with matching partition keys is stored and retrieved from a single node. Data queries that pull data from remote datastores or different partition keys, or data that is located on more than a single node, takes longer to complete. The reason is due to the additional I/O reads necessary to retrieve all the data from potentially numerous remote locations. Recall from Table 7.3 that both Azure Stream Analytics and Azure Event Hubs use the concept of partitions for scalability; in this context, however, a partition is synonymous with a node rather than data structuring.
To achieve optimal processing of streamed data, you need to understand the different meanings of partitioning and how to implement them in each context. Table 7.6 summarizes which Azure products can be used with Azure Stream Analytics, whether they can be configured as inputs or outputs, and whether they support partitioning. To achieve the processing of data streams using a single partition requires that both Azure Stream Analytics input and output products support partitioning and that the number of partitions in the input and output aliases match. For example, if the input event hub has two partitions, the output event hub must also have two partitions.
TABLE 7.6 Stream Analytics input/output partitioning
| Product | Direction | Partition |
| Event Hubs | Input/output | Explicit |
| IoT Hub | Input/output | Explicit |
| Blob Storage | Input/output | Explicit |
| ADLS | Input/output | Implicit |
| Cosmos DB | Output | Explicit |
| Service Bus | Output | Implicit |
| Synapse Analytics | Output | Implicit |
| Power BI | Output | Not supported |
The Partition column in Table 7.6 may need more explanation. The “Implicit” value means that a partition key is provided as part of the default metadata, which is sent along with the streamed data, whereas the “Explicit” value means the partition key must be provided from the client as part of the data stream. Take a look in the Program.cs file located on GitHub in the Chapter07/Ch07Ex03 directory. You will not find a partition key. To explicitly provide a partition key to the event hub from the client, which can then be used by the Azure Stream Analytics job, you update the code to something similar to the following code snippet:
IEnumerable<EventData> eventDataList = new List<EventData>()
{ eventData };CancellationToken cancellationToken = new CancellationToken();SendEventOptions eventOptions = new SendEventOptions(){ PartitionKey = “pkBrainwavesPOW” };await producerClient.SendAsync(eventDataList, eventOptions, cancellation Token);
When running in compatibility level 1.2 (the default) or greater, Azure Stream Analytics will automatically use the provided partition key to create a subset of your data. Older compatibility levels of Azure Stream Analytics require that you use PARTITION BY, as in the following example:
SELECT *
INTO Output
FROM Input PARTITION BY pkBrainwavesPOW
When a partition key is explicitly or implicitly provided, the subset of data with matching partition keys is processed on the same Azure Stream Analytics partition. Consider a scenario where you have many clients streaming data to your Azure Stream Analytics job, each one having a unique partition key. In this case, Azure Stream Analytics will process the data streams with different partition keys on different partitioned nodes in parallel, as illustrated in Figure 7.31.
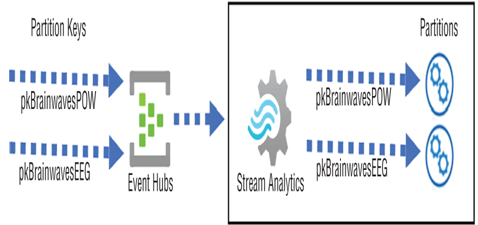
FIGURE 7.31 Partition key mapping to Azure Stream Analytics partitions
Without a partition key, the numerous BCIs that produce either POW or EEG brain waves and stream them to the same Event Hubs endpoint would not be grouped together. This would result in a random partition being selected to process the data stream, not in parallel. Using a partition key is much more efficient than processing the variety of data across all nodes sequentially. Finally, notice in Table 7.6 that Power BI does not support partitions, which means that optimal throughput of data streams through Azure Stream Analytics cannot be attained. This doesn’t mean performance or throughput is inadequate; it means that when compared to an implementation that can use partition keys for input and output that support partitioning, performance would be slower for products that don’t support partition keys.


