
To confirm the messages passed through Event Hubs and the Azure Stream Analytics job, navigate to the Overview blades of each product and view the consumption metrics. You will see something similar to Figure 7.15.
The first action you took in Exercise 7.3 was to confirm that the input Event Hubs connection from the Azure Stream Analytics job created in Exercise 3.17 is still working. Next, you started your SQL pool in the Azure Synapse Analytics workspace you created in Exercise 3.3 and created a table named [brainwaves].[BrainwaveMedians] to store the data streamed from your Azure Stream Analytics job. Then, you created the output connection between the two named synapse. In Exercise 7.1 you created an output connection to an ADLS container, which means the Azure Stream Analytics job is configured to send output to both an ADLS container and an Azure Synapse Analytic dedicated SQL pool. This is accomplished by adding an additional T‐SQL query that contains an INTO statement that points to synapse. The query that contains the INTO statement for the ADLS container remains as well. After saving the query, starting the Azure Stream Analytics job, configuring the event hub, and confirming that the SQL pool is running, you can send the data stream for processing. Note that the Azure Stream Analytics job must be stopped in order for you to modify the query.
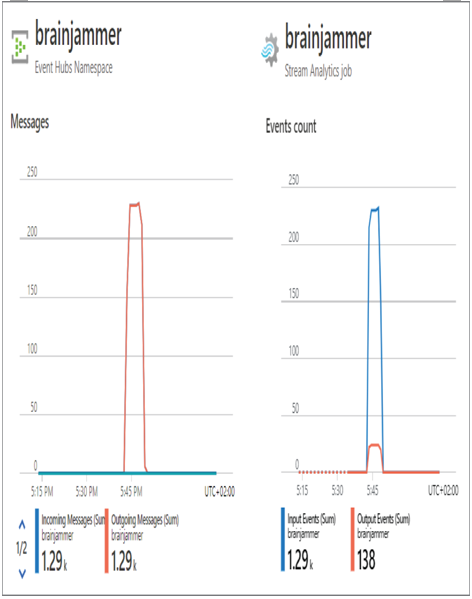
FIGURE 7.15 Develop a stream processing solution Azure Stream Analytics sent to Event Hub and Azure Stream Analytics.
The compressed file contains code that simulates what a BCI would send to an event hub. It is unlikely that you have a BCI, so this example file will allow you to simulate the real scenario.
There is a fun exercise on the Microsoft Docs website that walks you through sending IoT messages with a virtual Raspberry Pi. The instructions are at https://docs.microsoft.com/en-us/azure/stream-analytics/quick-create-visual-studio-code#run-the-iot-simulator, and the link is in the Chapter07 directory on GitHub.
Two brainjammer brain wave session files are included in the ZIP file that you downloaded from GitHub: csharpguitar‐brainjammer‐pow‐1244.json is a meditation scenario, and csharpguitar‐brainjammer‐pow‐0904.json is a metal music scenario. Either file can be used with the brainjammer.exe application. However, any file in the BrainwaveData/SessionJson//POW directory on GitHub (https://github.com/benperk/ADE) can be used with the application. You need to enter the event hub connection string, which is accessible on the Shared Access Policies blade of the event hub. The name of the event hub (not the Event Hubs namespace name) and the brainjammer brain wave session filename and location make up the event hub connection string. Once the complete brain wave stream has passed though the Azure Stream Analytics job and into the Azure Synapse Analytics SQL pool, you can view the results. The following query and the results tell an interesting story: SELECT Scenario, COUNT() FROM [brainwaves].[BrainwaveMedians] GROUP BY Scenario
The number of readings in the streamed brain wave session file was 1,286. The time frame of the windowing function was 5 seconds, as per the value in the following query:
TumblingWindow(second, 5)
The query run against the [brainwaves].[BrainwaveMedians] table returned 69 rows. This means the aggregate functions that calculated the median ran on 1286 / 69 = 18.6 readings. Additional EDA or a change in the time frame might result in a more desired outcome. This is something that will be done outside the context of this book. However, it is something that you can also pursue, because you now have the skills and experience to progress this forward. It might be that every scenario requires its own time window configuration, which would make the Azure Stream Analytics query very complex. There are many approaches for taking this forward to a working solution, which explains the point about the complexities and challenges of finding insights of data and then using them. Before progressing onto the Power BI portion of the solution, one additional topic that relates to Azure Stream Analytics needs to be covered: accessing and using reference data from an Azure Stream Analytics query.
Reference Data
Reference data is a set of numeric data that is used to look up a human‐readable value. The numeric value is commonly a primary or foreign key. Reference data or reference tables are very common in the relational database model. You will also see this kind of reference data in the context of slowly changing dimensional tables, which have been covered in much detail throughout this book. Consider the following table, for example, which is not very helpful or comprehensible:
If you had a reference table that contained a mapping between the numeric ID number and a human‐readable value, the result of a query like the following would be much easier to understand:
SELECT FREQUENCY.FREQUENCY, READING.VALUE, READING.READING_DATETIME
FROM READING
JOIN FREQUENCY ON READING.FREQUENCY_ID = FREQUENCY.FREQUENCY_ID
Using reference data from an Azure Stream Analytics query is possible. You can either use a file that contains the reference data, which is stored in either an Azure Blob Storage or an ADLS container, or create a reference table in an Azure SQL database. To reference data stored in an ADLS container, complete Exercise 7.4.


