
In Exercise 7.6 you created a stream processing solution using Azure Databricks. That stream processing solution used the Append output mode and displayed the data stream in the console, as illustrated in Figure 7.28. This was achieved using the following Scala code snippet:
messages.writeStream.outputMode(“append”).format(“console”).
option(“truncate”, false).start().awaitTermination()
As with Azure Stream Analytics, there are numerous ways in which upserting can be implemented. Two options are discussed in the following text, starting with a delta table solution. You would first need a delta table to store the incoming data stream, which can be achieved using the following code snippet, which is followed by code that loads the table into a reference object:
Writing the data stream is where you would implement the upsert logic. The first portion of the code notifies the runtime that the format of the data is to be structured in delta format. The foreachBatch() method iterates through all the streamed data for the given time window and attempts to merge it with the data on the existing data on the brainwaves delta table.
The instantiation of the messages object is not displayed; however, it is the same as you performed in Exercise 7.6 and is shown in the sample source code on GitHub. The code for this example is in the Chapter07 directory in the brainwaveUpsert.scala Databricks notebook source file. The ID used to determine if a record already exists is within the Time column. If a match is found, the updateAll() method is called; otherwise, the insertAll() method is executed. Also notice the parameter value passed to the outputMode() method. Output mode was covered in detail in Chapter 6, where you learned that when Update is set as the Output mode, an aggregate is required; in this case, it is the value in the Time column. Instead of data being appended to the end of the table, an update is performed.
Another approach for implementing upserts in Azure Databricks is to use the MERGE SQL command. This is almost identical to the implementation you read about in the previous discussion concerning upserts Azure Stream Analytics to Azure Synapse Analytics.
The first line of code creates a temporary view that contains the current batch of streamed data. The next lines of code perform the MERGE SQL statement, which either updates matching records or inserts new ones.
Handle Schema Drift
Schema drift was introduced in Chapter 2, where you learned what a schema is and that schemas can, and often do, change. In Chapter 4 you learned about schema drift in the context of a Data Flow activity that exposes an option to allow schema drifting (refer to Figure 4.25). Consider the following JSON document, which is expected to be received from an IoT device like a BCI:
The baseline schema definition for that document would resemble the following. Notice that the schema provides a description of the value and its expected data type.
As time progresses and new devices and the software they use are updated, it is very possible that the format of the data being produced will deviate from the baseline. That deviation is referred to as schema drift. Consider that the newest version of the JSON document produced by the BCI now contains a value for MODE and modification to the ReadingDate data type. The newest document and schema would resemble the following:
The question is, how can you manage this schema drift in the context of a stream processing solution, as shown in Figure 7.37?
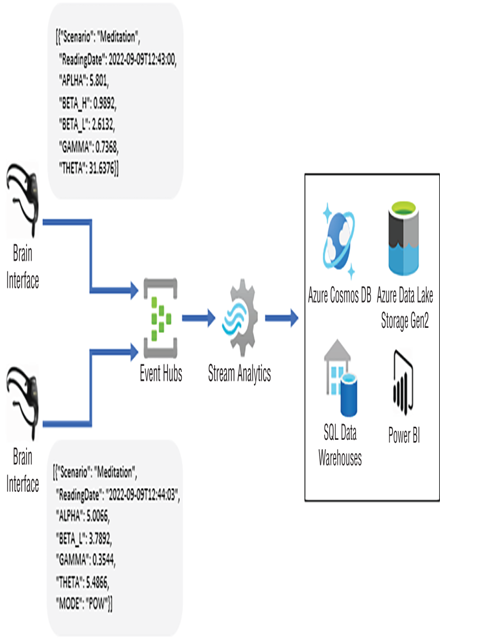
FIGURE 7.37 Handling schema drift in a stream processing solution
You would want to avoid creating new Event Hubs endpoints for every different kind of stream producer. You also would avoid that approach for each new software version of those data producers. The same goes for your Azure Stream Analytics job; it would not be optimal to have a job either for each data producer or for each schema variation produced. For any medium‐ to large‐scale stream processing solution, that approach would be too costly, not only from a cloud consumption cost perspective but also from a maintenance and support perspective. You would end up with too many endpoints and too many jobs. An alternative would be to optimize the Azure Stream Analytics query, as you will do Exercise 7.9.


