An alternative to using Azure Stream Analytics for real‐time or near real‐time stream processing is Azure Databricks. If your current streaming solution uses Kafka and your team’s primary programming language is Java, then Azure Databricks would be a good choice. Figure 7.24 illustrates how you can use Kafka to send event messages to Event Hubs that would then get consumed by an Apache Spark cluster in Azure Databricks.
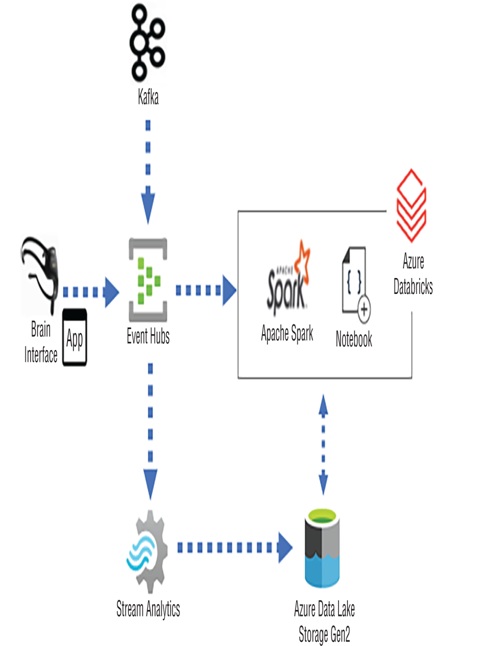
FIGURE 7.24 Azure Databricks stream processing
The reason you might choose to send Kafka messages to Event Hubs is to use Azure Stream Analytics, which exposes built‐in ingestion capabilities—for example, all the output sinks shown in Figure 7.5. It is possible that your data analytics solution does not require ingestion and transformation products other than what is offered in the Azure Databricks product. If this is the case, you can consume Kafka event messages directly from an Apache Spark cluster. Read on to learn a bit more about the streaming capabilities available in Azure Databricks. Keep in mind that there will be a tendency to include Microsoft products when working with products on the Azure platform.
Kafka
Kafka was introduced in Chapter 2, where the concept of Spark streaming was first discussed, and covered again in detail in Chapter 3, in the context of Azure HDInsight and the comparison with Event Hubs. This section compares some programming logic between the Event Hubs and Kafka client data producers. Beginning with Event Hubs, you can see in the Program.cs file, in the directory Chapter07/Ch07Ex03, the library that contains the message producer. The following code builds the client and then sends the message data to Event Hubs:
using Azure.Messaging.EventHubs.Producer;
EventHubProducerClient producerClient = new
EventHubProducerClient(EventHubConnectionString, EventHubName);
await producerClient.SendAsync(eventBatch);
The approach is similar when you are producing messages and streaming them to Kafka, in that you first include the library, then instantiate the client, and, finally, send the message.
package com.kafka.client;
import org.apache.kafka.clients.producer.KafkaProducer;
KafkaProducer producer = new KafkaProducer(properties);
producer.send(rec);
In both scenarios the details that define the endpoint to which the message is sent are part of the client building. That is the place where you decide if the messages are sent to Event Hubs or directly to an Apache Spark cluster that is listening for the arrival of the data.
readStream and writeStream
The producers of data use client libraries to package the message and send the data to an ingestion point. The location where the messages are ingested and processed is typically called server‐side. The server, in this scenario, is a machine that has been configured to receive these messages, perform data transformation, and then store the data. Instead of storing the data, the code on the server could stream the messages for instant consumption. You have already learned how this is done using Azure Stream Analytics, and in Exercise 7.6 you will learn how to do this in Azure Databricks.
When data is streamed into the Spark Structured Streaming pipeline, it is first stored on an input table. This table is unbounded and will grow as large as necessary to store all streamed data as it arrives. The queries and operations you perform against the data stream are done against the data in the input table. The output of those queries and operations is stored in a table referred to as the results table. Figure 7.25 represents this flow. The results table is where data is taken from to be stored on external data sources like ADLS or an Azure Synapse Analytics Spark pool.
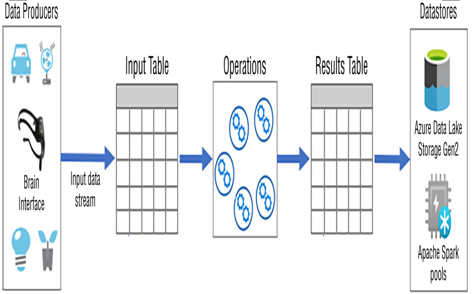
FIGURE 7.25 Azure Databricks Spark Structured Streaming
Two primary methods are used to work with data streams passing through an Apache Spark cluster, readStream() and writeStream(), both of which are part of the Spark stream processing engine. Configuring the server‐side consumer of messages requires that you subscribe to the endpoint that notifies your code when a message arrives. When a message notification arrives, the readStream() method is triggered to then pull the message from the message ingestion point. Once the message is received from either a socket or event hub, the data can be transformed and written to a console, to a delta table, to an ADLS container, or to any supported datastore. The write process is achieved by using the writeStream() method.
Windowing Functions
This concept is not new. Windowing functions are temporal windows that let you capture streamed data for a given time frame, group, or partition, and then run aggregate functions on that data. Windowing in Spark is achieved using the Window class, groupBy(), window(), or partitionBy() methods. Consider the following example, which groups data in 10‐second windows, updated every 5 seconds, and which would be run against the input table:
val messageCount = incomingStream.
groupBy(window($”timestamp”, “10 seconds”, “5 seconds”), $”Body”).count()
Aggregate functions such as AVG, SUM, MIN, and MAX are all supported and can be used to produce the output required for your solution. To get some hands‐on experience with streaming data to an Apache Spark cluster in Azure Databricks, complete Exercise 7.6.


