
- Log in to the Azure portal at https://portal.azure.com➢ navigate to the Azure Stream Analytics job you created in Exercise 3.17➢ select Outputs from the navigation menu on the Outputs blade ➢ select the + Add drop‐down menu ➢ and then select Blob Storage.
- Enter a name (I used ADLS) ➢ select the Select Blob Storage/ADLS Gen2 from the Your Subscription radio button ➢ select the subscription ➢ select the Azure storage account you created in Exercise 3.1➢ select the Use Existing radio button in the Container section ➢ select the ADLS container you want to store the data in (I used brainjammer) ➢ select Connection String from the Authentication Mode drop‐down list ➢ and then enter the following into the Path Pattern text box:
EMEA/brainjammer/in/{date}/{time} - Set the Date Format field to YYYY/MM/DD, and then set the Time Format field to HH. Figure 7.8 shows how the configuration should look.
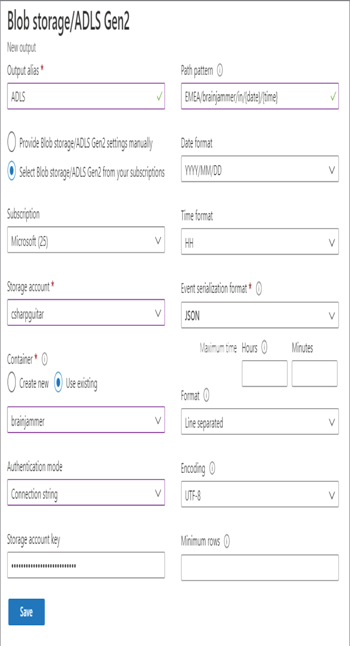
FIGURE 7.8 Azure Stream Analytics ADLS output
- Click Save.
The data selected by the query that runs on the streamed data in Azure Stream Analytics and stored into the ADLS output should resemble Figure 7.9.

FIGURE 7.9 Azure Stream Analytics ADLS container path and file
The file added to this container could then be used by any Azure data analytics product to perform more transformation and EDA to find business insights. An interesting option you might have noticed while configuring this output is the path pattern. The path pattern has been discussed in many places throughout this book for good reason. The options supported by the path pattern are flexible, which allows for some very powerful scenarios, starting with the prepended directory path of EMEA/brainjammer/in with the year, month, day, and hour appended to it. This pattern has been shown throughout the book and is an optimal directory structure for the ingestion of streamed data. You might instead want to implement the DLZ pattern and use something like EMEA/brainjammer/cleansed‐data as the directory path to store your data. Another option is to use one of the columns from the SELECT statement as a value for the storge directory. For example, if the brain wave readings being sent to Azure Stream Analytics included a column named scenario, it could be used as a column name. If the scenario is MetalMusic, then you could use the following example to access the scenario value, which is used as the folder name:
EMEA/brainjammer/cleansed-data/{scenario}
In Exercise 4.2 you implemented partitioning in Azure Synapse Analytics using an Apache Spark pool. You used a DataFrame and the partitionBy()method, which looks something similar to the following code snippet. The output of that code resulted in a folder structure like the one shown in Figure 4.3.
df.write \
.partitionBy(‘SCENARIO’).mode(‘overwrite’).csv(‘/path/ScenarioPartitions’)
The result illustrated in Figure 4.3 can be queried by using the following path pattern example:
{path}/SCENARIO={scenario}
Having the data partitioned in such a way is optimal for running PySpark code on an Apache Spark pool or cluster. The code snippet to perform the query using the partition is provided here as a reminder.
spark.read.csv(‘path/SCENARIO=MetalMusic’).show()
A few other configurable options are available for this blob storage/ADLS Gen2 output. For example, there are eight different date formats to choose from. When {date} is added to the path pattern, the Date Format drop‐down list is enabled. The default is YYYY/MM/DD, but you can choose DD‐MM‐YYYY, MM‐DD‐YY, MM/DD/YYYY, and many others. When {time} is added to the path pattern, the Time Format drop‐down list is enabled. The three options are HH (the default), HH‐mm, and HH/mm. JSON was selected as the event serialization format. The other options are CSV, ARVO, and Parquet. It would make a lot of sense to select Parquet as the file type if you plan to perform additional transformations on the data using an Apache Spark pool or cluster. In that scenario you should also consider using the partitioning approach using the partitionBy()method.


